usare l'intelligenza artificiale per classificare gli articoli di giornale
In questo esperimento di utilizzo dell'intelligenza artificiale applicata ai contenuti del web vengono riportati i metodi per classificare un contenuto in base alla sua apparteneza 'politica', ossia in base all'area di riferimento dei quotidiani.
L'esperimento viene condotto utilizzando un numero limitato di pagine di esempio; nel caso si voglia eseguirlo su scala più ampia è sufficiente aumentare il numero di esempi da prendere in considerazione.
la raccolta dei dati
In una prima fase vengono scaricate le pagine principali dei giornali che costituiranno la base del ragionamento.
Le testate vengono analizzate il giorno 26 dicembre 2018 e sono:
- http://www.repubblica.it
- http://www.ilsecoloxix.it/
- http://www.ilfoglio.it
- http://www.corriere.it
- http://www.gazzetta.it/
- http://www.ilsole24ore.com/
- http://www.ilmessaggero.it/
- http://www.avvenire.it/
- http://www.ilrestodelcarlino.it/
- http://www.corrieredellosport.it/
- http://www.liberoquotidiano.it/
- http://www.lanazione.it/
- http://www.tuttosport.com/
- http://www.gazzettino.it/
- http://www.ilfattoquotidiano.it/
- http://www.unionesarda.it/
- http://www.quotidiano.net/
Procederemo a 'marcare' queste testate a seconda del loro raggruppamento, ottenuto tramite algoritmi di intelligenza artificiale applicati ai contenuti delle home page.
Il raggruppamento delle testate viene effettuato tramite gli argomenti che hanno in comune; l'analisi degli argomenti per ogni giornale viene effettuata tramite algoritmo LDA (Latent Dirichlet Allocation).
Sui testi delle home page viene eseguita una preparazione dei contenuti scaricati, eliminando ovviamente quanto non è utile (tag html, per esempio) e mantenendo quanto invece è contenuto utile al raggruppamento.
In particolare vengono effettuati:
- conversione in minuscolo di tutte le parole
- eliminazione delle parole più corte di tre caratteri
- eliminazione delle punteggiature
- eliminazione dele parole appartenenti ad una lista di termini inutili
| natale | 308 |
| 2018 | 175 |
| dicembre | 168 |
| condividi | 143 |
| foto | 97 |
| video | 95 |
| 89 | |
| sport | 82 |
| calcio | 79 |
| 79 | |
| serie | 69 |
| articolo | 63 |
| roma | 57 |
| news | 56 |
| cronaca | 55 |
| notizie | 54 |
| economia | 53 |
| motori | 52 |
| mostra | 51 |
| italia | 50 |
| politica | 48 |
| sconto | 48 |
| catania | 42 |
| manovra | 42 |
Questi termini non sembrano utili al raggruppamento di cui abbiamo bisogno.
Proviamo ora a lanciare un 'topic extractor' con 'Parallel LDA'; è necessario prestabilire un numero di argomenti desunti dai contenuti delle pagine con cui vogliamo lavorare; in una prima fase, anche in base ad esperienze passate, fissiamo in 8 il numero di argomenti da utilizzare.
Ogni argomento in LDA viene definito da un certo numero di termini; il numero di termini che definiscono un argomento è anch'esso regolabile, in questo caso definiamo il valore di 12. Avremo quindi 8 argomenti definiti ognuno da dodici termini.
Ecco gli 8 argomenti (topic) estratti ed i termini che li descrivono:
| topic_0 | foto, commenta, foglio, lapresse, perché, editoriali, papa, santo, redazione, popotus, matteo, francesco |
| topic_1 | 2018, dicembre, manovra, sole, fisco, natale, mercati, articoli, guida, 2019, tecnologia, futuro |
| topic_2 | sconto, natale, cronaca, calcio, ancona, marche, codice, esteri, firenze, prato, messa, milano |
| topic_3 | serie, calcio, mostra, natale, notizie, sport, gazzetta, news, juventus, motori, formula, classifica |
| topic_4 | natale, video, articolo, foto, sport, 2018, italia, catania, dicembre, motori, genova, salute |
| topic_5 | condividi, politica, economia, cronaca, manovra, società, lobby, magazine, giustizia, giornalista, entra, buon |
| topic_6 | twitter, facebook, messenger, natale, cagliari, provincia, libero, sardegna, salvini, trump, sassari, standard |
| topic_7 | condividi, natale, commenti, vigilia, notte, news, lauto, altre, guarda, manovra, quotidiano, choc |
Per ognuna delle fonti giornalistiche LDA assegna un valore di appartenenza più o meno alto ad uno degli argomenti, 'assegnando' una testata all'argomento per la quale essa ha valore più alto:
| http://www.repubblica.it | 7.796238343996486E-5 | 7.476949718992777E-5 | 0.2230596366235333 | 0.22490635251228536 | 0.32120287664078884 | 0.23057914124510054 | 4.717523965002032E-5 | 5.20858580120428E-5 | topic_4 |
| http://www.ilsecoloxix.it/ | 0.09079014132621897 | 0.08894928579431151 | 0.02951120414950459 | 5.013037621659187E-5 | 0.7826735325544999 | 2.1392240609370323E-5 | 0.007987684595450054 | 1.662896318899486E-5 | topic_4 |
| http://www.ilfoglio.it | 0.7851555323573204 | 3.8978853641118376E-5 | 1.2054947484875298E-4 | 8.18578280114559E-5 | 0.1874780078908062 | 0.027073326774229124 | 2.459340815321863E-5 | 2.7153412989608616E-5 | topic_0 |
| http://www.corriere.it | 4.172988996118277E-5 | 0.12239499838725944 | 0.09574572934098939 | 0.0720575623180084 | 0.709670984710318 | 3.5865183500852164E-5 | 2.5250864232539964E-5 | 2.787930573018043E-5 | topic_4 |
| http://www.gazzetta.it/ | 5.8770391467172224E-5 | 5.636349769936777E-5 | 0.08271363348700898 | 0.8385440777188095 | 0.07850181808369375 | 5.051081793763985E-5 | 3.556211572115847E-5 | 3.926388766229186E-5 | topic_3 |
| http://www.ilsole24ore.com/ | 1.714949656013758E-5 | 0.9101906352055533 | 5.086592986527814E-5 | 3.4539964141517684E-5 | 0.08924768479661711 | 4.3729000219036633E-4 | 1.0377204677492786E-5 | 1.1457400394860798E-5 | topic_1 |
| http://www.ilmessaggero.it/ | 2.5990122734866666E-5 | 2.492571831499879E-5 | 0.050026498762431516 | 0.02054441159818782 | 0.3773177137059224 | 2.233747853068248E-5 | 1.572669041724373E-5 | 0.5520223959234605 | topic_7 |
| http://www.avvenire.it/ | 0.7641558406759946 | 6.221986705779273E-5 | 1.9242670315639727E-4 | 1.306652890155729E-4 | 0.23532048769864403 | 5.575907289897619E-5 | 3.9257146961785176E-5 | 4.334354627085734E-5 | topic_0 |
| http://www.ilrestodelcarlino.it/ | 4.399147656885672E-5 | 4.218984128709685E-5 | 0.998417927071185 | 8.86010862122087E-5 | 0.0013134719929875423 | 3.7808927391927515E-5 | 2.6619356132078313E-5 | 2.9390248235163644E-5 | topic_2 |
| http://www.corrieredellosport.it/ | 3.0365302491686767E-5 | 2.912171612957172E-5 | 9.006441334670315E-5 | 0.9936418129080825 | 0.006143877022177142 | 2.6097771811434738E-5 | 1.83741229921963E-5 | 2.0286742968711875E-5 | topic_3 |
| http://www.liberoquotidiano.it/ | 3.704490427373912E-5 | 3.552776023233555E-5 | 0.018365047641597358 | 0.006463920297911098 | 0.2356850168007061 | 0.04749528407097227 | 0.6918934092088176 | 2.4749315489533766E-5 | topic_6 |
| http://www.lanazione.it/ | 4.536839242797987E-5 | 4.351036667276253E-5 | 0.9994862518640053 | 9.137426525179325E-5 | 2.3674009685633265E-4 | 3.899233190122821E-5 | 2.745253147595512E-5 | 3.031015140857092E-5 | topic_2 |
| http://www.tuttosport.com/ | 4.203241200978251E-5 | 4.031100862984001E-5 | 1.2466941602983826E-4 | 0.9984483672558574 | 0.0012549793796111568 | 3.6125189189728313E-5 | 2.543392110577034E-5 | 2.808141756634578E-5 | topic_3 |
| http://www.gazzettino.it/ | 2.858990401801571E-5 | 2.7419027661993362E-5 | 0.0036069671377189816 | 5.758153052067045E-5 | 0.17555318384807517 | 2.457188731702136E-5 | 1.7299824788701687E-5 | 0.8206843868398995 | topic_7 |
| http://www.ilfattoquotidiano.it/ | 2.330392848556301E-5 | 2.234953497486821E-5 | 6.912016266922975E-5 | 4.693530515168555E-5 | 0.25391414193238226 | 0.7458944787566064 | 1.4101267336701446E-5 | 1.5569112393241906E-5 | topic_5 |
| http://www.unionesarda.it/ | 1.9667594981625684E-5 | 0.02909454659385292 | 0.04900240354322383 | 0.013123669554471504 | 0.2947362315250254 | 0.0038936614462067053 | 0.6101166800264615 | 1.3139715776393183E-5 | topic_6 |
| http://www.quotidiano.net/ | 4.242787472184653E-5 | 4.069027548692835E-5 | 0.9002074138329914 | 8.545191203453189E-5 | 0.09953353219236839 | 3.6465073688563895E-5 | 2.5673216614592657E-5 | 2.8345622093718716E-5 | topic_2 |
Ad ogni colonna corrisponde il valore assegnato per l'argomento, da topic_0 a topic_7; nell'ultima colonna l'argomento assegnato alla testata.
A questo punto si può tentare una rappresentazione nello spazio dei valori ottenuti, così da avere una prima impressione sulla coerenza dei risultati.
Per rappresentare sullo spazio bidimensionale le testate giornalistiche i valori dell atabella precedente vengono ridotti a due dimensioni tramite un processo di riduzione dimensionale (PCA); ad ogni argomento (topic) viene assegnato un colore diverso.
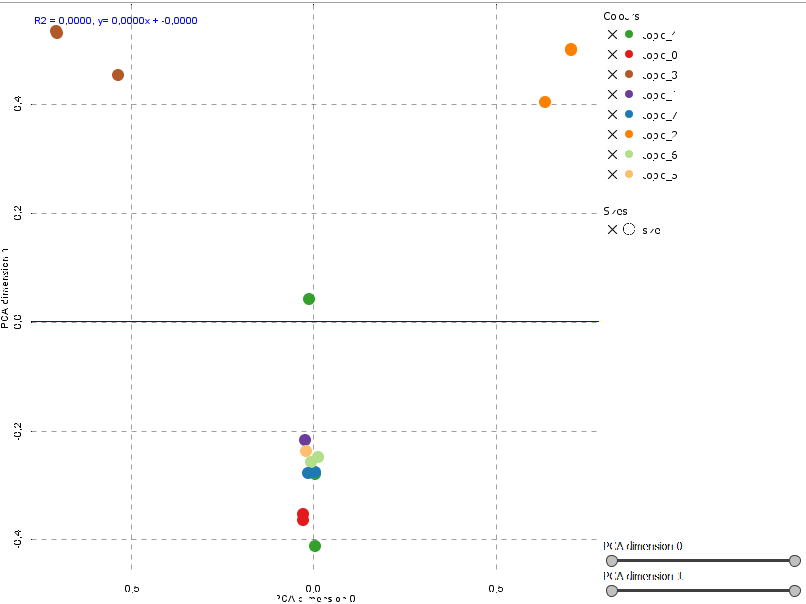
Tenendo conto che ogni punto rappresenta una delle 17 testate vediamo che i punti con colore (=argomento assegnato) simile sono vicini, questo ci conferma la validità dell'analisi LDA.
Tuttavia questo non è sufficiente per classificare in una zona 'politica' le nostre testate, ma solo per classificarle in un dato piuttosto grezzo che è l'argomento assegnato.
Possiamo fare un passo avanti utilizzando un 'classico' dell'intelligenza artificiale, ovvero la sua capacità di raggruppamento (o clusterizzazione).
Utilizziamo l'algoritmo K-means che ci consente di raggruppare le testate in un certo numero di gruppi o clusters; il raggruppamento lo facciamo eseguire in base a tutti i pesi degli argomenti (tabella precedente) calcolati, e non solo in base all'argomento assegnato come abbiamo fatto per l'ultimo grafico.
Anche nel caso fi K-means dobbiamo indicare il numero di raggruppamenti che vogliamo utilizzare: in questo caso indichiamo il valore di 5, per avere 5 zone 'politiche' nelle quali suddividere i nostri giornali.
Utilizzando la stessa riduzione dimensionale per la rappresentazione bidimensionale prima effettuata rappresentiamo le testate con un colore diverso questa volta a seconda del raggruppamento o cluster, e non dell'argomento come fatto prima; questo il risultato:
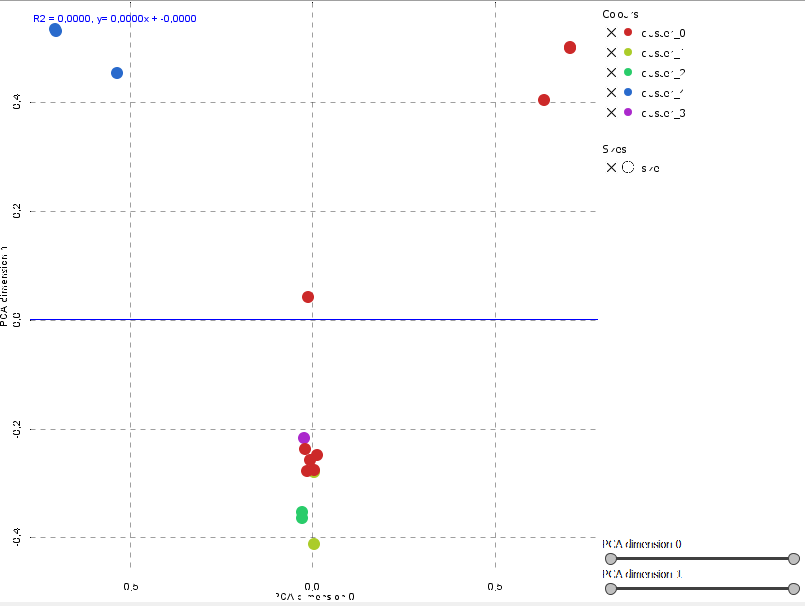
Questa volta avremo più punti dello stesso colore perchè appartenenti a testate dello stesso cluster; quasi sempre i colori vengono a trovarsi nella stessa zona dello spazio bidimensionale, evidenziando la coerenza tra l'analisi LDA ed il raggruppamento K-Means pur nella riduzione del PCA.
Ecco il risultato del raggruppamento:

Naturalmente quanto questa suddivisione sia 'politica' nel senso stretto del termine è discutibile, ma l'appartenenza allo stesso gruppo di argomenti è palese; si veda il caso viola dei quotidiani sportivi.
Volendo rappresentare i dati in tre dimensioni per una visione più accurata è sufficiente impostare PCA per ridurre i valori a 3 in modo da utilizzarli per lo spazio:
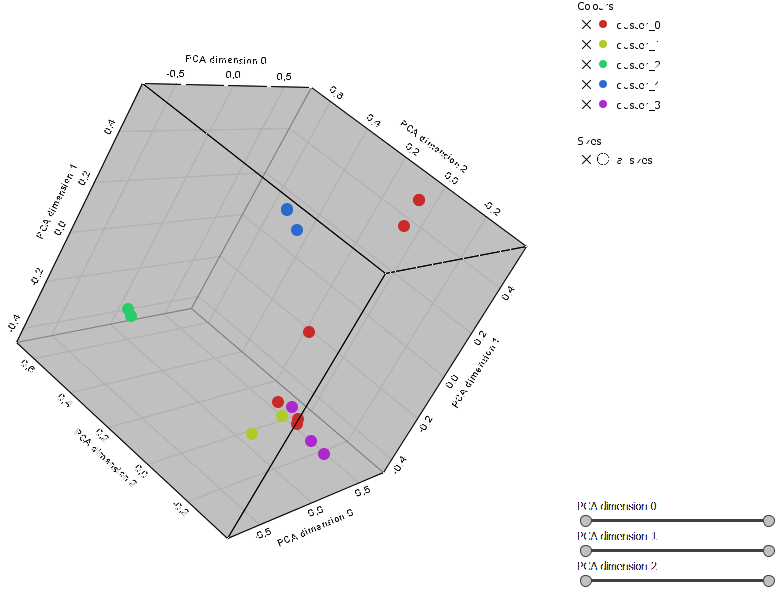
Per una più precisa collocazione delle testate in gruppi più omogenei 'politicamente' si può procedere iin questo modo:
- incrementare il numero di pagine analizzate, magari utilizzandone un certo numero risultanti dalla ricerca per keyword prefissate su ogni testata (es.: tutte le risposte alla richiesta 'governo')
- utilizzare algoritmi più evoluti rispetto ad LDA; in particolare tutti quelli di deep learning legati al word embedding possono risultare più completi, mettendo in relazione le parole tra loro a seconda dei reciproci rapporti di vicinanz
Lo vedremo nel prossimo articolo.
Biblio / linkografia
Node description for Topic Extractor (Parallel LDA)
Newman, Asuncion, Smyth and Welling, Distributed Algorithms for Topic Models JMLR (2009), with SparseLDA sampling scheme and data structure from Yao, Mimno and McCallum, Efficient Methods for Topic Model Inference on Streaming Document Collections, KDD (2009).
Node description for PCA
Principal component analysis (PCA)